
Synthetic Data Is Eating Real | 매거진에 참여하세요
Synthetic Data Is Eating Real
#artifial #data #simulation #training #Synthetic #Data #Economy #Market #Size




Synthetic Data Is Eating the Real Market
Fake data is no longer just a supplement—it’s becoming the foundation of AI.
In 2025, data is still the crude oil of the AI industry. But relying solely on real-world data has hit a wall.
Privacy regulations, rising collection costs, and biases baked into datasets have forced companies to look elsewhere.
Enter synthetic data—artificially generated data created by AI models and simulations.
Photos, videos, text, even sensor data that never existed in the real world can now be fabricated at scale. And paradoxically, this “fake” data is proving to be even more useful for training modern AI.
Why Synthetic Data Matters
The rise of synthetic data is not an accident—it’s a response to the growing limitations of real-world datasets:
Privacy barriers: Regulations like GDPR and CCPA make collecting and sharing customer data increasingly difficult.
Cost: Training autonomous cars on real crash data requires millions of miles on the road. With simulations, it takes only a few clicks.
Scarcity: Medical datasets for rare diseases or industrial accident records are extremely difficult to obtain. Synthetic generation fills that gap.
Bias correction: Real data reflects societal biases. Synthetic data allows fine-grained control to create balanced training sets.
In short, synthetic data has become a key to data democratization.
It lowers barriers and makes AI development possible for companies that could never afford to collect massive real-world datasets.

Industries Already Transformed
1. Autonomous Driving
Every major player—Waymo, Tesla, Hyundai—relies heavily on simulation.
Scenarios like rain-slick highways, jaywalking pedestrians, or broken traffic lights are dangerous and rare in real life,
but trivial to reproduce endlessly in virtual environments.
2. Healthcare
Synthetic MRI scans and patient records allow model training without compromising privacy.
GE Healthcare trains diagnostic models on synthetic scans of rare conditions.
NVIDIA Clara provides synthetic image libraries to hospitals worldwide, enabling “collaboration without data sharing.”
3. Robotics
Physical robots can’t afford millions of trial-and-error runs. But in synthetic environments, they can fail billions of times in a single day.
OpenAI’s robotic hand experiments have shown that simulation-based training can drastically accelerate real-world performance.
The Market for Fake Data
The global synthetic data market is projected at $3 billion in 2025, and is expected to surpass $20 billion by 2030.
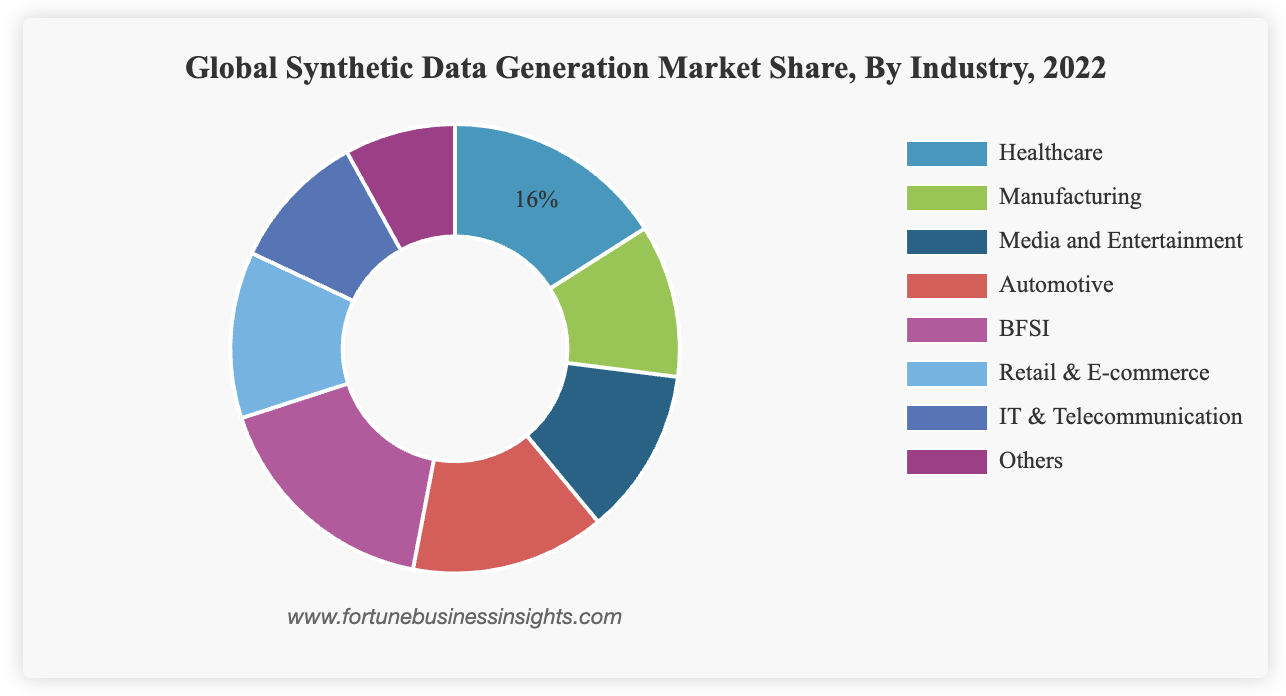
Key players include:
Mostly AI – Vienna-based pioneer specializing in privacy-safe customer data for finance.
Synthesis AI – San Francisco startup creating massive synthetic datasets for computer vision.
Gretel.ai – API-first platform making synthetic data generation as easy as writing code.
NVIDIA Omniverse – A digital twin environment generating photorealistic training data at scale.
The shift is economic as much as technical. Companies are starting to subscribe to synthetic datasets rather than purchase raw data.
Data itself is becoming a product.
Challenges Ahead
Not everyone is convinced. Critics point to several unresolved issues:
Fidelity gaps – Simulated data still struggles to fully capture the messiness of the real world.
Bias transfer – Poorly designed synthetic data can amplify the very biases it was meant to fix.
Liability – When an AI trained on fake data makes a bad decision, who’s responsible? The model maker or the data generator?
Standards are emerging. ISO and IEEE are already working on frameworks for verifying the quality of synthetic datasets.
The Truth of the Fake
Synthetic data is no longer a gimmick or a backup plan—it’s becoming the default.
It solves for:
Data that’s impossible to collect
Data that’s illegal to share
Data that’s too dangerous to capture
In the near future, the distinction between “real” and “fake” data will matter less than one question: How well was it made?
The Synthetic Data Economy has already begun and it’s on track to redefine the standard for AI development.

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
